Facial Expression and Landmark Tracking (FELT) dataset
Creators

- 1. Ontario Tech University
-
2.
 Toronto Metropolitan University
Toronto Metropolitan University
Description
Contact Information
If you would like further information about the Facial expression and landmark tracking data set, or if you experience any issues downloading files, please contact us at ravdess@gmail.com.
Facial Expression examples
Watch a sample of the facial expression tracking results.
Commercial Licenses
Commercial licenses for this dataset can be purchased. For more information, please contact us at ravdess@gmail.com.
Description
The Facial Expression and Landmark Tracking (FELT) dataset dataset contains tracked facial expression movements and animated videos from the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) [RAVDESS Zenodo page]. Tracking data and videos were produced by Py-Feat 0.6.2 (2024-03-29 release) (Cheong, J.H., Jolly, E., Xie, T. et al. Py-Feat: Python Facial Expression Analysis Toolbox. Affec Sci 4, 781–796 (2023). https://doi.org/10.1007/s42761-023-00191-4) and custom code (github repo). Tracked information includes: facial emotion classification estimates, facial landmark detection (68 points), head pose estimation (yaw, pitch, roll, x, y), and facial Action Unit (AU) recognition. Videos include: landmark overlay videos, AU activation animations, and landmark plot animations.
The FELT dataset was created at the Affective Data Science Lab.
This dataset contains tracking data and videos for all 2452 RAVDESS trials. Raw and smoothed tracking data are provided. All tracking movement data are contained in the following archives: raw_motion_speech.zip, smoothed_motion_speech.zip, raw_motion_song.zip, and smoothed_motion_song.zip. Each actor has 104 tracked trials (60 speech, 44 song). Note, there are no song files for Actor 18.
Total Tracked Files = (24 Actors x 60 Speech trials) + (23 Actors x 44 Song trials) = 2452 CSV files.
Tracking results for each trial are provided as individual comma separated value files (CSV format). File naming convention of raw and smoothed tracked files is identical to that of the RAVDESS. For example, smoothed tracked file "01-01-01-01-01-01-01.csv" corresponds to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4". For a complete description of the RAVDESS file naming convention and experimental manipulations, please see the RAVDESS Zenodo page.
Landmark overlays, AU activation, and landmark plot videos for all trials are also provided (720p h264, .mp4). Landmark overlays present tracked landmarks and head pose overlaid on the original RAVDESS actor video. As the RAVDESS does not contain "ground truth" facial landmark locations, the overlay videos provide a visual 'sanity check' for researchers to confirm the general accuracy of the tracking results. Landmark plot animations present landmarks only, anchored to the top left corner of the head bounding box with translational head motion removed. AU activation animations visualize intensity of AU activations (0-1 normalized) as a heatmap over time. The file naming convention of all videos also matches that of the RAVDESS. For example, "Landmark_Overlay/01-01-01-01-01-01-01.mp4", "Landmark_Plot/01-01-01-01-01-01-01.mp4", "ActionUnit_Animation/01-01-01-01-01-01-01.mp4", all correspond to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4".
Smoothing procedure
Raw tracking data were first low-pass filtered with a 5th order butterworth filter (cutoff_freq = 6, sampling_freq = 29.97, order = 5) to remove high-frequency noise. Data were then smoothed with a Savitzky-Golay filter (window_length = 11, poly_order = 5). Scipy.signal (v 1.13.1) was used for both procedures.
Landmark Tracking models
Six separate machine learning models were used by Py-Feat to perform various aspects of tracking and classification. Video outputs generated by different combinations of ML models were visually compared, with final model choice determined by voting of first and second authors. Models were specified in the call to Detector class (described here). Exact function call as follows:
Detector(face_model='img2pose', landmark_model='mobilenet', au_model='xgb', emotion_model='resmasknet', facepose_model='img2pose-c', identity_model='facenet', device='cuda', n_jobs=1, verbose=False, )
Default Py_feat parameters to each model were used in most cases. Non-defaults were specified in the call to detect_video function (described here). Exact function call as follows: (video_path, skip_frames=None, output_size=(720, 1280), batch_size=5, num_workers=0, pin_memory=False, face_detection_threshold=0.83, face_identity_threshold=0.8 )
Tracking File Output Format
This data set retained Py-Feat's data output format. The resolution of all input videos was 1280x720. Tracking output units are in pixels, their range of values is (0,0) (top left corner) to (1280,720) (bottom right corner).
Column 1 = Timing information
- 1. frame - The number of the frame (source videos 29.97 fps), range = 1 to n
Columns 2-5 = Head bounding box
- 2-3. FaceRectX, FaceRectY - X and Y coordinates of top-left corner of head bounding box (pixels)
- 4-5. FaceRectWidth, FaceRectHeightF - Width and Height of head bounding box (pixels)
Column 6 = Face detection confidence
- FaceScore - Confidence level that a human face was deteceted, range = 0 to 1
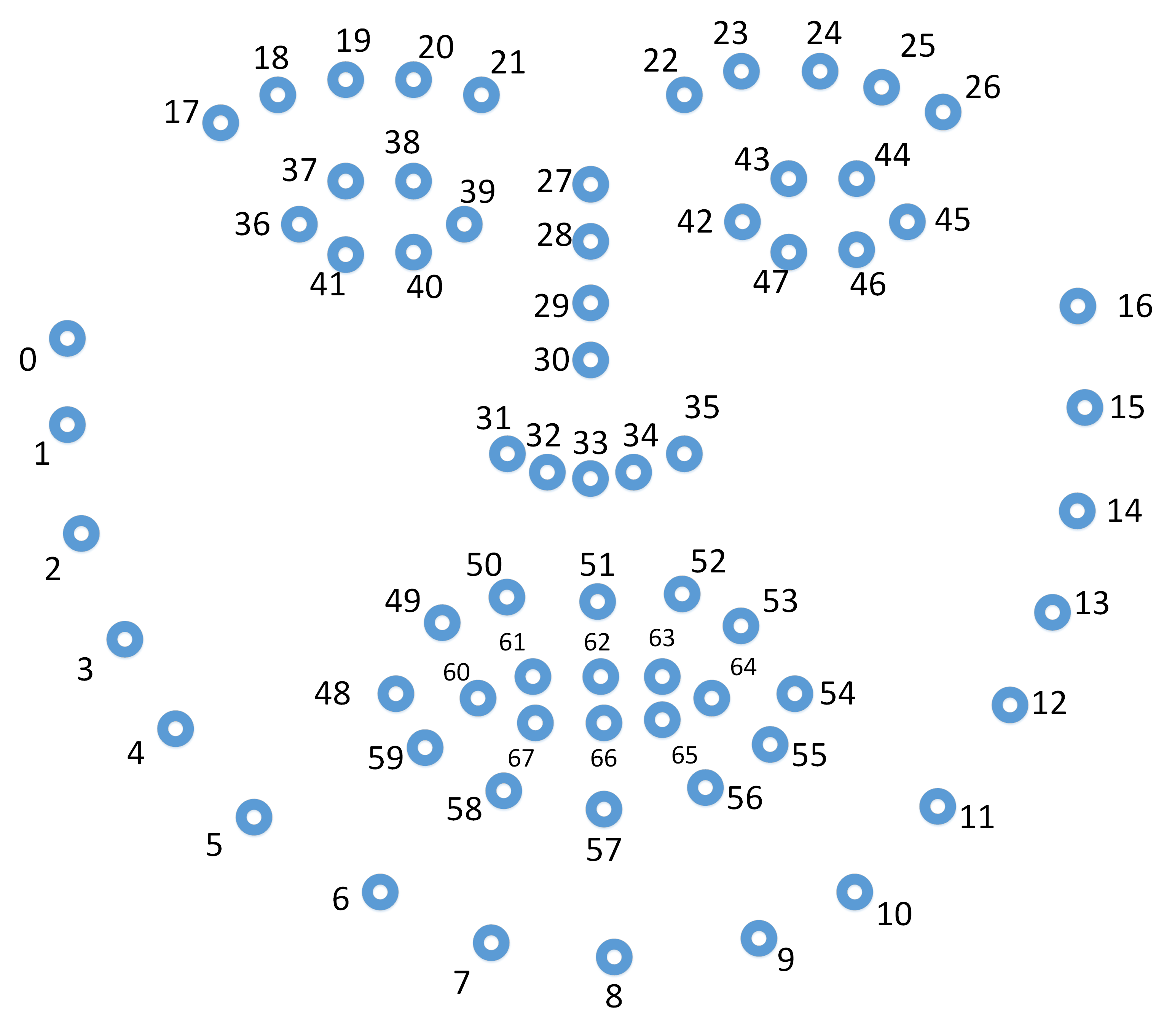
Columns 7-142 = Facial landmark locations in 2D
- 7-142. x_0, ..., x_67, y_0,...y_67 - Location of 2D landmarks in pixels. A figure describing the landmark index can be found here.
{kind=link}
Columns 143-145 = Head pose
- 143-145. Pitch, Roll, Yaw - Rotation of the head in degrees (described here). The rotation is in world coordinates with the camera being located at the origin.
Columns 146-165 = Facial Action Units
Facial Action Units (AUs) are a way to describe human facial movements (Ekman, Friesen, and Hager, 2002) [wiki link]. More information on Py-Feat's implementation of AUs can be found here.
- 145-150, 152-153, 155-158, 160-165. AU01, AU02, AU04, AU05, AU06, AU09, AU10, AU12, AU14, AU15, AU17, AU23, AU24, AU25, AU26, AU28, AU43 - Intensity of AU movement, range from 0 (no muscle contraction) to 1 (maximal muscle contraction).
- 151, 154, 159. AU07, AU11, AU20 - Presence or absence of AUs, range 0 (absent, not detected) to 1 (present, detected).
Columns 166-172 = Emotion classification confidence
- 162-172. anger, disgust, fear, happiness, sadness, surprise, neutral - Confidence of classified emotion category, range 0 (0%) to 1 (100%) confidence.
Columns 173-685 = Face identity score
Identity of faces contained in the video were classified using the FaceNet model (described here). This procedure generates at 512 dimension Euclidean embedding space.
- 173. Identity - Predicated individual identifyed in the RAVDESS video. Note, value is always Person_0, as each video only contains a single actor at all times (categorical).
- 174-685. Identity_1, ..., Identity_512 - Face embedding vector used by FaceNet to perform facial identity matching.
Column 686 = Input video
- 686. frame - The number of the frame (source videos 29.97 fps), range = 1 to n
Columns 687-688 = Timing information
- 687. frame.1 - The number of the frame (source videos 29.97 fps), duplicated column, range = 1 to n
- 688. approx_time - Approximate time of current frame (0.0 to x.x, in seconds)
Tracking videos
Landmark Overlay and Landmark Plot videos were produced with plot_detections function call (described here). This function generated invidual images for each frame, which were then compiled into a video using the imageio library (described here).
AU Activation videos were produced with plot_face function call (described here). This function also generated invidual images for each frame, which were then compiled into a video using the imageio library. Some frames could not be correctly generated by Py-Feat, producing only the AU heatmap but failing to plot/locate facial landmarks. These frames were dropped prior to compositing the output video. Drop rate was approximately 10% of all frames, in each video. Dropped frames were distributed evenly across the video timeline (i.e. no apparent clustering).
License information
The RAVDESS Facial expression and landmark tracking data set is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NA-SC 4.0.
How to cite the RAVDESS Facial Tracking data set
Academic citation
If you use the RAVDESS Facial Tracking data set in an academic publication, please cite both references:
- Liao, Z., Livingstone, SR., & Russo, FA. (2024). RAVDESS Facial expression and landmark tracking (Version 1.0.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.13243600
- Livingstone SR, Russo FA (2018). The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391.
All other attributions
If you use the RAVDESS Facial expression and landmark tracking dataset in a form other than an academic publication, such as in a blog post, data science project or competition, school project, or non-commercial product, please use the following attribution: "RAVDESS Facial expression and landmark tracking" by Liao, Livingstone, & Russo is licensed under CC BY-NA-SC 4.0.
Related Data sets
- The Ryerson Audio-Visual Database of Emotional Speech and Song [Zenodo project page].
Files
raw_motion_song.zip
Files
(5.4 GB)
| Name | Size | Download all |
|---|---|---|
|
md5:f46413a86bf74e329b46986acab29e89
|
834.7 MB | Preview Download |
|
md5:de7d11061808451964fa8b31a4b07aed
|
944.9 MB | Preview Download |
|
md5:b9a7ad6ad3ab18a76e64eb70a7576ff7
|
798.1 MB | Preview Download |
|
md5:d9956b6d2e25fdf8983dfd9e8cc62656
|
903.3 MB | Preview Download |
|
md5:f4939e17bf6d4b3c1171ac8b43f068c1
|
904.2 MB | Preview Download |
|
md5:0ea7ef3bb2f63e9d4b8bb398f18b59fa
|
1.0 GB | Preview Download |
Additional details
Related works
- Is derived from
- Dataset: 10.5281/zenodo.3255102 (DOI)
Dates
- Available
-
2024-08-20
Software
- Repository URL
- https://github.com/harveyliao/Py-feat-RAVDESS/
- Programming language
- Python
- Development Status
- Active
References
- Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391.