RAVDESS Facial Landmark Tracking
Authors/Creators

- 1. University of Wisconsin, River Falls
- 2. Ryerson University
Description
Contact Information
If you would like further information about the RAVDESS Facial Landmark Tracking data set, or if you experience any issues downloading files, please contact us at ravdess@gmail.com.
Tracking Examples
Watch a sample of the facial tracking results.
Description
The RAVDESS Facial Landmark Tracking dataset set contains tracked facial landmark movements from the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) [RAVDESS Zenodo page]. Motion tracking of actors' faces was produced by OpenFace 2.1.0 (Baltrusaitis, T., Zadeh, A., Lim, Y. C., & Morency, L. P., 2018). Tracked information includes: facial landmark detection, head pose estimation, facial action unit recognition, and eye-gaze estimation.
The Facial Landmark Tracking dataset was created in the Affective Data Science Lab.
This data set contains tracking for all 2452 RAVDESS trials. All tracking movement data are contained in "FacialTracking_Actors_01-24.zip", which contains 2452 .CSV files. Each actor has 104 tracked trials (60 speech, 44 song). Note, there are no song files for Actor 18.
Total Tracked Files = (24 Actors x 60 Speech trials) + (23 Actors x 44 Song trials) = 2452 files.
Tracking results for each trial are provided as individual comma separated value files (CSV format). File naming convention of tracked files is identical to that of the RAVDESS. For example, tracked file "01-01-01-01-01-01-01.csv" corresponds to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4". For a complete description of the RAVDESS file naming convention and experimental manipulations, please see the RAVDESS Zenodo page.
Tracking overlay videos for all trials are also provided (720p Xvid, .avi), one zip file per Actor. As the RAVDESS does not contain "ground truth" facial landmark locations, the overlay videos provide a visual 'sanity check' for researchers to confirm the general accuracy of the tracking results. The file naming convention of tracking overlay videos also matches that of the RAVDESS. For example, tracking video "01-01-01-01-01-01-01.avi" corresponds to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4".
Tracking File Output Format
This data set retained OpenFace's data output format, described here in detail. The resolution of all input videos was 1280x720. When tracking output units are in pixels, their range of values is (0,0) (top left corner) to (1280,720) (bottom right corner).
Columns 1-3 = Timing and Detection Confidence
- 1. Frame - The number of the frame (source videos 30 fps), range = 1 to n
- 2. Timestamp - Time of frame, range = 0 to m
- 3. Confidence - Tracker confidence level in current landmark detection estimate, range = 0 to 1
Columns 4-291 = Eye Gaze Detection
- 4-6. gaze_0_x, gaze_0_y, gaze_0_z - Eye gaze direction vector in world coordinates for eye 0 (normalized), eye 0 is the leftmost eye in the image (think of it as a ray going from the left eye in the image in the direction of the eye gaze).
- 7-9. gaze_1_x, gaze_1_y, gaze_1_z - Eye gaze direction vector in world coordinates for eye 1 (normalized), eye 1 is the rightmost eye in the image (think of it as a ray going from the right eye in the image in the direction of the eye gaze).
- 10-11. gaze_angle_x, gaze_angle_y - Eye gaze direction in radians in world coordinates, averaged for both eyes. If a person is looking left-right this will results in the change of gaze_angle_x (from positive to negative) and, if a person is looking up-down this will result in change of gaze_angle_y (from negative to positive), if a person is looking straight ahead both of the angles will be close to 0 (within measurement error).
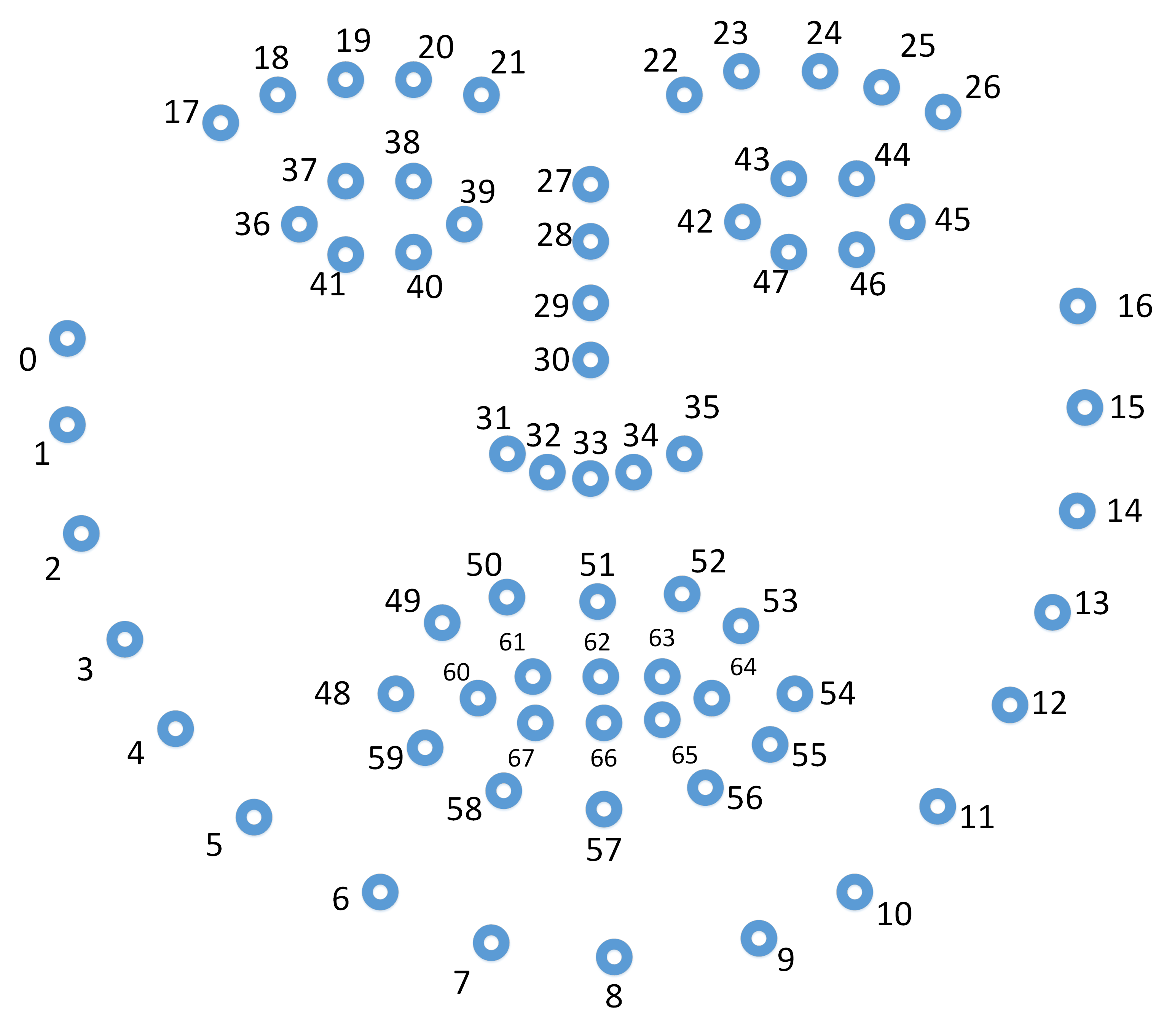
- 12-123. eye_lmk_x_0, ..., eye_lmk_x55, eye_lmk_y_0,..., eye_lmk_y_55 - Location of 2D eye region landmarks in pixels. A figure describing the landmark index can be found here.
- 124-291. eye_lmk_X_0, ..., eye_lmk_X55, eye_lmk_Y_0,..., eye_lmk_Y_55,..., eye_lmk_Z_0,..., eye_lmk_Z_55 - Location of 3D eye region landmarks in millimeters. A figure describing the landmark index can be found here.
{kind=link}
Columns 292-297 = Head pose
- 292-294. pose_Tx, pose_Ty, pose_Tz - Location of the head with respect to camera in millimeters (positive Z is away from the camera).
- 295-297. pose_Rx, pose_Ry, pose_Rz - Rotation of the head in radians around X,Y,Z axes with the convention R = Rx * Ry * Rz, left-handed positive sign. This can be seen as pitch (Rx), yaw (Ry), and roll (Rz). The rotation is in world coordinates with the camera being located at the origin.
Columns 298-433 = Facial Landmarks locations in 2D
- 298-433. x_0, ..., x_67, y_0,...y_67 - Location of 2D landmarks in pixels. A figure describing the landmark index can be found here.
{kind=link}
Columns 434-637 = Facial Landmarks locations in 3D
- 434-637. X_0, ..., X_67, Y_0,..., Y_67, Z_0,..., Z_67 - Location of 3D landmarks in millimetres. A figure describing the landmark index can be found here. For these values to be accurate, OpenFace needs to have good estimates for fx,fy,cx,cy.
Columns 638-677 = Rigid and non-rigid shape parameters
Parameters of a point distribution model (PDM) that describe the rigid face shape (location, scale and rotation) and non-rigid face shape (deformation due to expression and identity). For more details, please refer to chapter 4.2 of my Tadas Baltrusaitis's PhD thesis [download link].
- 638-643. p_scale, p_rx, p_ry, p_rz, p_tx, p_ty - Scale, rotation, and translation terms of the PDM.
- 644-677. p_0, ..., p_33 - Non-rigid shape parameters.
Columns 687-712 = Facial Action Units
Facial Action Units (AUs) are a way to describe human facial movements (Ekman, Friesen, and Hager, 2002) [wiki link]. More information on OpenFace's implementation of AUs can be found here.
- 678-694. AU01_r, AU02_r, AU04_r, AU05_r, AU06_r, AU07_r, AU09_r, AU10_r, AU12_r, AU14_r, AU15_r, AU17_r, AU20_r, AU23_r, AU25_r, AU26_r, AU45_r - Intensity of AU movement, range from 0 (no muscle contraction) to 5 (maximal muscle contraction).
- 695-712. AU01_c, AU02_c, AU04_c, AU05_c, AU06_c, AU07_c, AU09_c, AU10_c, AU12_c, AU14_c, AU15_c, AU17_c, AU20_c, AU23_c, AU25_c, AU26_c, AU28_c, AU45_c - Presence or absence of 18 AUs, range 0 (absent, not detected) to 1 (present, detected).
Note, OpenFace's columns 2 and 5 (face_id and success, respectively) were not included in this data set. These values were redundant as a single face was detected in all frames, in all 2452 trials.
Tracking Overlay Videos
Tracking overlay videos visualize most aspects of the tracking output described above.
- Frame - Column 1, Top left corner of video
- Eye Gaze - Columns 4-11. Indicated by green ray emanating from left and right eyes.
- Eye region landmarks 2D - Columns 12-123. Red landmarks around left and right eyes, and black circles surrounding left and right irises.
- Head pose - Columns 292-297. Blue bounding box surrounding the actor's head.
- Facial landmarks 2D - Columns 298-433. Red landmarks on the participant's left and right eyebrows, nose, lips, and jaw.
- Facial Action Unit Intensity - Columns 687-694. All 17 AUs are listed on the left side of the video in black text. Intensity level (0-5) of each AU is indicated by the numeric value and blue bar.
- Facial Action Unit Presence - Columns 695-712. All 18 AUs are listed on the right side of the video in black & green text. Absence of an AU (0) is in black text with the numeric value 0.0. Presence of an AU (1) is in green text with the numeric value 1.0.
Camera Parameters and 3D Calibration Procedure
This data set contains accurate estimates of actors' 3D head poses. To produce these, camera parameters at the time of recording were required (distance from camera to actor, and camera field of view). These values were used with OpenCV's camera calibration procedure, described here, to produce estimates of the camera's focal length and optical center at the time of actor recordings. The four values produced by the calibration procedure (fx,fy,cx,cy) were input to OpenFace as command line arguments during facial tracking, described here, to produce accurate estimates of 3D head pose.
Camera Parameters
- Distance between camera and actor = 1.4 meters
- Camera field of view = 0.5 meters
- Focal length in x (fx) = 6385.9
- Focal length in y (fy) = 6339.6
- Optical center in x (cx) = 824.241
- Optical center in y (cy) = 1033.6
The use of OpenCV's calibration procedure was required as the video camera used in the RAVDESS recordings did not report focal length values. Unlike SLR cameras, most video cameras do not provide this information to the user due to their dynamic focus feature. For all RAVDESS recordings, camera distance, field of view, and focal point (manual fixed camera focus) were kept constant.
License information
The RAVDESS Facial Landmark Tracking data set is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, CC BY-NA-SC 4.0.
How to cite the RAVDESS Facial Tracking data set
Academic citation
If you use the RAVDESS Facial Tracking data set in an academic publication, please cite both references:
- Swanson, R., Livingstone, SR., & Russo, FA. (2019). RAVDESS Facial Landmark Tracking (Version 1.0.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3255102
- Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391.
All other attributions
If you use the RAVDESS in a form other than an academic publication, such as in a blog post, school project, or non-commercial product, please use the following attribution: "RAVDESS Facial Landmark Tracking" by Swanson, Livingstone, & Russo is licensed under CC BY-NA-SC 4.0.
Related Data sets
- The Ryerson Audio-Visual Database of Emotional Speech and Song [Zenodo project page].
Notes
Files
FacialTracking_Actors_01-24.zip
Files
(10.6 GB)
| Name | Size | Download all |
|---|---|---|
|
md5:5753bbc64a9a790f8a8d3e03cba526ee
|
417.2 MB | Preview Download |
|
md5:f12cf8570928860bb2dc8f9854ba14ca
|
401.8 MB | Preview Download |
|
md5:0b49fa47615bd635d2fc5bceaa2942bb
|
391.3 MB | Preview Download |
|
md5:41bfc48b65e4c9d4a93b803896413623
|
456.7 MB | Preview Download |
|
md5:1790d91062d6c179c6b1705063be8901
|
400.5 MB | Preview Download |
|
md5:bf4602e009c346224dfa5cad19907820
|
408.6 MB | Preview Download |
|
md5:ee2933efd7b391cef0f042437bc34489
|
424.0 MB | Preview Download |
|
md5:d17882bc7e2987fe54106f658a762b9a
|
444.1 MB | Preview Download |
|
md5:69c9e3d1c89d33310ea7832cd7fba8ef
|
455.7 MB | Preview Download |
|
md5:a06d8766c1c1bbdf65f7ff89b2e06689
|
429.5 MB | Preview Download |
|
md5:0b4fa8b74348aa74b46b15a5f6e06400
|
414.7 MB | Preview Download |
|
md5:83096acd17b3d493a9e69f9321865e72
|
440.7 MB | Preview Download |
|
md5:930d422e64373ad86f14b47c1605a590
|
376.2 MB | Preview Download |
|
md5:e475f7033e28c9aaaae7465c2c883db9
|
381.1 MB | Preview Download |
|
md5:984ff469b0aacbeb229327530326df43
|
450.3 MB | Preview Download |
|
md5:5df31cbf346087199c4d55d0e3b6a322
|
437.1 MB | Preview Download |
|
md5:0eb5d0a94752c691c07752c23dbeb880
|
478.4 MB | Preview Download |
|
md5:f5d279911e063871325237cb4ef4a090
|
497.7 MB | Preview Download |
|
md5:7fdaa0f61c38552da66f2398e5deb9a0
|
244.6 MB | Preview Download |
|
md5:cf7a707a65448a9d61140fb0eeff63e8
|
442.6 MB | Preview Download |
|
md5:78a731cc1579fe8da36ce678dfa035db
|
444.0 MB | Preview Download |
|
md5:9ecc943e9b63dd2130403f7108080934
|
411.2 MB | Preview Download |
|
md5:17e293829c1a371ca95283204c2aa615
|
455.5 MB | Preview Download |
|
md5:a7d8f76b0675b5d9d5aa544161006cf6
|
444.7 MB | Preview Download |
|
md5:4b04591a54f371fbb669d34cb28e1c7c
|
467.4 MB | Preview Download |
Additional details
Related works
- References
- 10.5281/zenodo.1188976 (DOI)
- 10.1371/journal.pone.0196391 (DOI)
References
- Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391