Published January 24, 2024
| Version v1
Dataset
Open
Mudestreda Multimodal Device State Recognition Dataset

Description
Mudestreda Multimodal Device State Recognition Dataset
obtained from real industrial milling device with Time Series and Image Data for Classification, Regression, Anomaly Detection, Remaining Useful Life (RUL) estimation, Signal Drift measurement, Zero Shot Flank Took Wear, and Feature Engineering purposes.
The official dataset used in the paper "Multimodal Isotropic Neural Architecture with Patch Embedding" ICONIP23.
Official repository: https://github.com/hubtru/Minape
Conference paper: https://link.springer.com/chapter/10.1007/978-981-99-8079-6_14
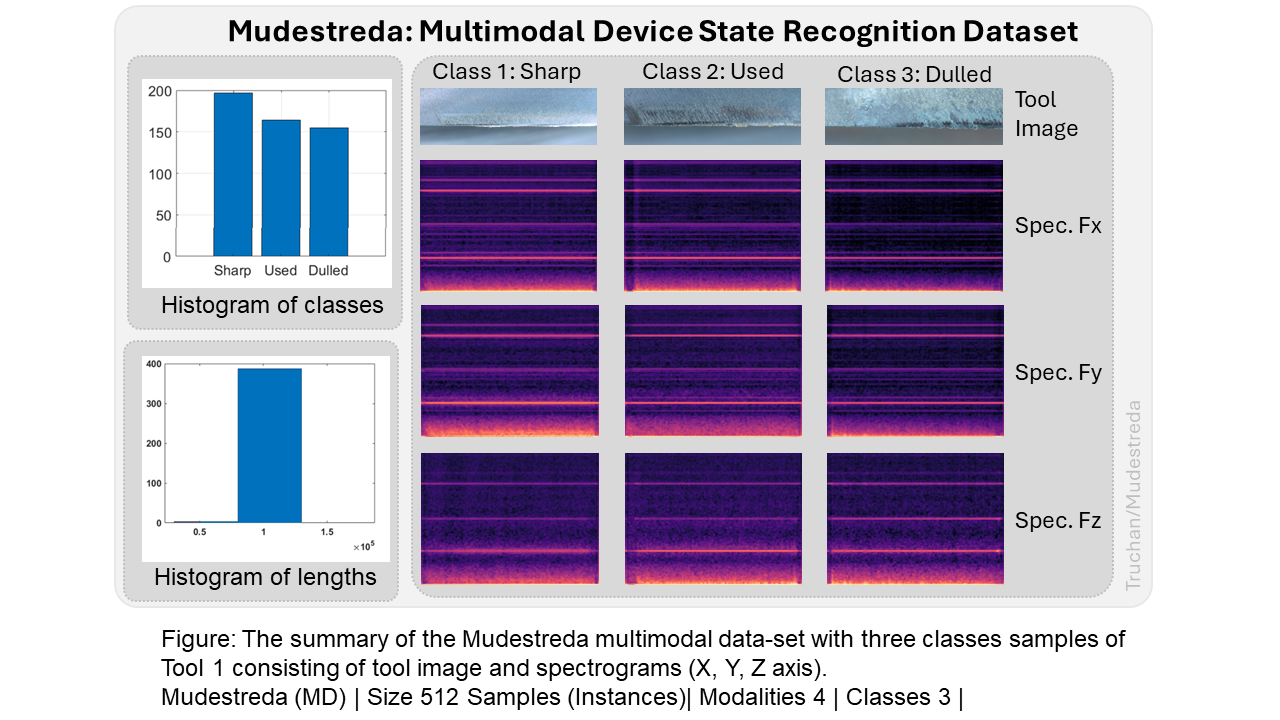
Mudestreda (MD) | Size 512 Samples (Instances, Observations)| Modalities 4 | Classes 3 |
Future research: Regression, Remaining Useful Life (RUL) estimation, Signal Drift detection, Anomaly Detection, Multivariate Time Series Prediction, and Feature Engineering.
Notice: Tables and images do not render properly.
Recommended: `README.md` includes the Mudestreda description and images `Mudestreda.png` and `Mudestreda_Stage.png`.
Data Overview
- Task: Uni/Multi-Modal Classification
- Domain: Industrial Flank Tool Wear of the Milling Machine
- Input (sample): 4 Images: 1 Tool Image, 3 Spectrograms (X, Y, Z axis)
- Output: Machine state classes: `Sharp`, `Used`, `Dulled`
- Evaluation: Accuracies, Precision, Recal, F1-score, ROC curve
-
Each tool's wear is categorized sequentially: Sharp → Used → Dulled.
-
The dataset includes measurements from ten tools: T1 to T10.
- Data splitting options include random or chronological distribution, without shuffling.
- Options:
- Original data or Augmented data
- Random distribution or Tool Distribution ([see Dataset Splitting](#dataset-spliting))
Abstract (English)
Abstract
The rapid advancement in multimodal datasets primarily featuring images, audio, and text, coupled with transformer-based architectures, has been undeniable. However, many real-world industrial scenarios necessitate a distinct approach, focusing on industrial-grade imagery and multivariate time series data from sensors, suitable for deployment on efficient edge devices. This shift is driven by two major limitations of existing multimodal open-source datasets:
(i) they are often constrained to specific modalities, typically centered around video data, limiting their adaptability,
and (ii) they predominantly feature general-purpose objects, which do not address domain-specific and industrial challenges effectively.
Addressing these gaps, we introduce the Mudestreda dataset, a novel multimodal industrial device state recognition resource. Mudestreda uniquely showcases the multimodal nature of industrial tool wear, comprising 512 samples with four-dimensional observations: three force signal sequences and one RGB image of a shaft milling tool, collected over five weeks from a Production Centrum.
Our dataset reveals a strong correlation between tool wear and force amplitude increases, signifying progressive tool deterioration. Mudestreda models tool wear across three states: sharp, used, and dulled. Each tool's transition is captured as a temporal sequence, enabling two distinct approaches: treating each observation independently or as correlated sequential data. The former facilitates learning individual sample representations (tool image and three spectrograms), while the latter allows for modelling state dependencies, ideal for memory-based or recurrent neural network architectures.
Additionally, Mudestreda supports experimentation with multimodal classifiers, enabling independent unimodal analysis and comparative performance assessment across varying numbers of modalities. In our current work, we emphasize the dataset's capability in multimodal classification, evaluating the impact of modality count on performance.
Other (English)
Future Work
We aim to extend our research to Remaining Useful Life (RUL) estimation, considering the final observation of each tool (T1-T10) as the endpoint of its lifecycle. We also plan to explore fault and anomaly detection, treating the 'Dulled' class as an anomaly.
Our dataset design, with tools T1-T8 for training, T9 for validation, and T10 for testing, simulates zero-shot scenarios, challenging models to generalize to new, unseen conditions. This setup is vital for studying zero-shot learning and its industrial applications, like predictive tool wear adaptation.
Future endeavours will also focus on feature engineering, developing a Diagnostic Feature Designer app for feature importance assessment and selection. This includes extracting blade shapes from RGB tool images, segmenting flank wear, and processing time series data through various techniques like temporal window-based features, Fourier Transforms, Wavelet Transforms, Decomposition, Domain-Specific Features (e.g. RMS (Root Mean Square) Forces, Harmonic Analysis of signals, Spectral Kurtosis, Enveloping or Demodulation Techniques and Cross-Correlation Features.
We are also expanding the dataset to include additional modalities such as:
- Acoustic emission to monitor the sound emitted by the machinery,
- Temperature Monitoring as high temperatures can indicate excessive friction,
- Power consumption that can be used to indicate the machine's efficiency,
- Torque and Load Analysis can reveal issues with the load on the machinery,
- Speed Variations may signal problems with tool wear,
- Contamination Levels of machining residues.
We are working on the multi-regression labels:
- Flank wear [µm],
- Gaps [µm],
- Overhang [µm],
These additions aim to enrich the dataset for multivariate time series prediction, signal drift measurements, and precise flank tool wear estimation.
In conclusion, the Mudestreda dataset presents a unique industrial multimodal device state recognition benchmark for advancing machine learning, neural network and feature engineering methodologies. It is designed for developing and testing lightweight, fast, and explainable algorithms suitable for practical, domain-specific industrial applications and real-life edge-device implementation.
Technical info (English)
Use Cases
| Input | Model | Output |
|
4 Images (1 Tool Image, 3 Spectrograms (X, Y, Z))
|
Classification Model
|
Class (Flank Tool Wear: `Sharp`, `Used`, `Dulled`)
|
|
3 Spectrograms (X,Y,Z axis)
|
Classification Model
|
Class (Flank Tool Wear: `Sharp`, `Used`, `Dulled`)
|
|
1 Tool Image
|
Classification Model
|
Image Class (Flank Tool Wear: `Sharp`, `Used`, `Dulled`)
|
Future work use cases
| Input | Model | Output |
|
[1, ..., 4] Images
|
Model
|
Remaining Useful Life (RUL) estimation
|
|
[1, ..., 4] Images
|
Monitoring Model
|
Fault and Anomaly Detection
|
|
[1, ..., 4] Images
|
Forecasting Model
|
Multivariate Time Series Prediction
|
|
[1, ..., 3] Spectrograms
|
Model
|
Signal Drift measurement
|
|
[1, ..., 4] Images
|
Regression Model
|
Zero-Shot Flank Tool Wear (in µm, 10e-6 meter)
|
|
[1, ..., 4] Images
|
Feature Engineering
|
Diagnostic Feature Designer
|
Technical info (English)
Sample Count
- Original Data:
- Random Split: Train 410 | Validation 54 | Test 48 | Total 512
- Tool Split: Train 404 | Validation 52 | Test 56 | Total 512
- Augmented Labels:
- Random Split: Train 2460 | Validation 54 | Test 48 | Total 2562
- Tool Split: Train 2424 | Validation 52 | Test 56 | Total 2532
Validation and Test sets are constant for reproducibility and comparison.
Augmented Dataset (`dataset_aug`): 3072 files
Augmentation creates 'Aug' prefixed images.
The difference beetween the 2562 and 3072 comes from the fact that the augumented are as well the validaiton and the test images, however thay are not considered in the validation and the test process.
Augumentation:
If you want to test augumentation techniques run `minape/augumentation` scripts. After running the augumentation script the new labels_train_augumented.csv file is created with varying number of the training instances.
Technical info (English)
Data Collection
We collected the data from the DMG MORI HSC 55 5-axis linear milling machine, using ten shaft milling tools and a C45 tempered steel work-piece, over eight weeks from the Production Centrum.
The signal collecting system comprises a dynamometer (KISTLER 9257B), placed between the machine bench and workpiece holder, an amplifier (KISTLER 5011), a bus-coupler (BECKHOFF EK1100), and the industrial PC (BECKHOFF C6920) for decoding and saving the recorded data.
We have captured three-dimensional time series modalities data using a dynamometer sensor positioned beneath the processed material, which measures forces along three axes (Fx, Fy, Fz) at a high sampling frequency of 10 kHz.The one-dimensional visual modality is the image of the tool taken with a Keyence VHX- S15F profile measurement unit microscope.
The milling phase begins when the tool plunges six millimetres into the workpiece and two millimetres in the radial direction. The milling machine continues constant, slow movement until the tool is outside a workpiece. The spindle head is then lifted and moved to the start position with an offset of two millimetres into the material in the radial direction, and the milling phase is repeated until the tool is destroyed or sparks prevent further machining.
Following each phase of processing, the tool is removed from the milling machine and transported to the measurement stand. Here, utilizing an industrial microscope, a detailed image of the tool is captured. This image facilitates the direct measurement of flank wear, allowing us to categorize each observation into a specific class, as defined by expert-established metrics.
| Class | Range | Description |
| Class-1 |
[0,71) µm
|
Sharp |
| Class-2 |
[71,110) µm
|
Used |
| Class-3 |
[110,+\infty) µm
|
Dulled |
- Naming: T- Tool, R- Ride, B- Blade, e.g. T1R2B3 referes to Tool_1, Ride_2, Blade_3.
- 10 Tools: T1 - T10
- Each Tool (T) → 10-15 Rides (R) → 4 Blades (B) per Ride
- Transition: Sharp → Used → Dulled
Technical info (English)
Data Structure
The strucuture of the main `Mudestreda` dataset folder:
data/
│
├── dataset_aug/
│ ├── spec_x/
│ ├── spec_y/
│ ├── spec_z/
│ └── tool/
│
├── dataset_original/
│ ├── spec_x/
│ ├── spec_y/
│ ├── spec_z/
│ └── tool/
│
├── labels_aug/
│ ├── random_distribution/
│ │ ├── train.csv
│ │ ├── val.csv
│ │ └── test.csv
│ └── tool_distribution/
│ ├── train.csv
│ ├── val.csv
│ └── test.csv
│
├── labels_original/
│ ├── random_distribution/
│ │ ├── train.csv
│ │ ├── val.csv
│ │ └── test.csv
│ └── tool_distribution/
│ ├── train.csv
│ ├── val.csv
│ └── test.csv
│
└── README.md
Technical info (English)
Dataset Spliting
Two types of train/val/test split were used:
- Random-based distribution
- Tool-based distributions
1 Random Distributions
A classic approach with an 80/10/10\% random training/validation/test split.
- Samples from all 10 tools (T1 - T10) are randomly allocated.
- Distribution Ratio: Training 80% | Validation 10% | Test 10%
| Data Pool Description |
| T1R1B1, T2R3B2, T3R2B4, T4R1B3, ..., T10R14B4 |
| Data Split | Tool # | Sample Size (Original, Augumented) |
| Training (80%) | Mixed Tools | (410, 2460) |
| Validation (10%) | Mixed Tools | (54, 54) |
| Test (10%) | Mixed Tools | (48, 48) |
2 Tool-based Distributions
In the Mudestreda Monitoring Dataset, each tool transitions from a sharp to a dull state, represented as a sequence of samples. This approach allows for learning not only the representation of individual samples (tool image and three spectrograms) but also the progression between states. By assigning samples from tools T1-T8 to the training dataset, T9 to validation, and T10 to the test set, without shuffling, the dataset facilitates learning long-term dependencies and state transitions, ideal for models with memory blocks or recurrent neural networks (RNNs).
This tool-based distribution simulates real-life zero-shot scenarios, where the test set, derived from a different tool, challenges the model to generalize its learning to new, unseen conditions. This aspect is crucial for studying zero-shot learning mechanisms and has significant implications for real-world applications, such as predicting tool wear and adapting to new conditions in industrial settings. The dataset offers a unique resource for advancing machine learning, particularly in sequential prediction and understanding zero-shot learning in practical scenarios.
- Each tool represents a sequence: Sharp → Used → Dulled.
- Samples are divided chronologically without shuffling.
- Training: Tools T1 - T8 | Validation: Tool T9 | Test: Tool T10
| Samples from Tools T1-T10 |
| T1, T2, ..., T8, T9, T10 |
| Data Split | Tool # | Sample Size (Original/Augmented) |
| Training (80%) | T1 - T8 | 404 / 2424 |
| Validation (10%) | T9 | 52 / 52 |
| Test (10%) | T10 | 56 / 56 |
Technical info (English)
How to use the dataset with Minape repository
Repository link: https://github.com/hubtru/Minape
As a default notebooks use augmented data with random distribution.
To choose beetween
- original / augumented dataset
- and random / tool distribution follow the instructions.
To choose one of the option. Comment (by '#') or uncomment (remove '#') necessary code in the repository `Minape/jupyther notebooks/choose_notebook` in `Dataset acquisition` jupyther notebook cell.
1. Original dataset:
- Preparing the data: Copy the content of the dataset_original folder to './Data' folder with the respect to file stricture described above. uncomment "Original dataset" part in "Dataset acquisition" cell in jupyter notebooks comment "Augmented dataset" part in "Dataset acquisition" cell in jupyter notebooks
- Preparing the labels:
- Option 1: Random distrubution
- uncomment "Random distribution" part in "Dataset acquisition" cell
- comment "Tool distribution" part in "Dataset acquisition" cell
- train the uni-modal models from /jupyter notebooks
- combine the models and train the `multi-reccurent_aug_toldist.ipynb`
- evaluate model using `mult-reccurent_aug_tooldist--evaluation.ipynb`
- Option 2: Tool based distribution
- uncomment "Tool distribution" part in "Dataset acquisition" cell
- comment "Random distribution" part in "Dataset acquisition" cell
- train the uni-modal models from /jupyter notebooks
- combine the models and train the `multi-reccurent_aug_toldist.ipynb`
- evaluate model using `mult-reccurent_aug_tooldist--evaluation.ipynb`
- Option 1: Random distrubution
2. Augumented dataset
- Preparing the data: Copy the content of the `dataset_aug.7z`` to the './Data/dataset_aug' folder.
- uncomment "Augmented dataset" part in "Dataset acquisition" cell in jupyter notebooks
- comment "Original dataset" part in "Dataset acquisition" cell in jupyter notebooks
- Preparing the labels:
- Option 1: Random distrubution
- uncomment "Random distribution" part in "Dataset acquisition" cell
- comment "Tool distribution" part in "Dataset acquisition" cell
- train the uni-modal models from /jupyter notebooks
- combine the models and train the multi-reccurent_aug_toldist.ipynb
- evaluate model using mult-reccurent_aug_tooldist--evaluation.ipynb
- Option 2: Tool based distribution
- uncomment "Tool distribution" part in "Dataset acquisition" cell
- comment "Random distribution" part in "Dataset acquisition" cell
- train the uni-modal models from /jupyter notebooks
- combine the models and train the multi-reccurent_aug_toldist.ipynb
- evaluate model using mult-reccurent_aug_tooldist--evaluation.ipynb
- Option 1: Random distrubution
Files
dataset_aug.zip
Files
(2.8 GB)
| Name | Size | Download all |
|---|---|---|
|
md5:da92f9d842e2298c7a6c1b10fc89d20e
|
2.6 GB | Preview Download |
|
md5:175550615d037f1c40d879390f340ee6
|
233.8 MB | Preview Download |
|
md5:5324471effe0d1f9da70064edf9792f2
|
13.2 kB | Preview Download |
|
md5:1d55cc26cf2f86139504bcea3bab4e39
|
4.8 kB | Preview Download |
|
md5:23871bddbb31a80103eb5c93f20992f7
|
431.2 kB | Preview Download |
|
md5:9aab085c0070b328ee5b347bf57d810a
|
579.9 kB | Preview Download |
|
md5:f1cc6363c14a78af16a06b1ed144fcc4
|
82.3 kB | Preview Download |
|
md5:05fb8235821aab12adb9e3afa2623739
|
83.9 kB | Preview Download |
|
md5:2130a05a6ffceeac87d12397f4bf4a00
|
17.4 kB | Preview Download |
{kind=link}
{kind=link}
Additional details
Identifiers
Related works
- Is supplement to
- Conference paper: 10.1007/978-981-99-8079-6_14 (DOI)
Dates
- Available
-
2024-01-24
References
- Truchan, H., Naumov, E., Abedin, R., Palmer, G., Ahmadi, Z. (2024). Multimodal Isotropic Neural Architecture with Patch Embedding. In: Luo, B., Cheng, L., Wu, ZG., Li, H., Li, C. (eds) Neural Information Processing. ICONIP 2023. Lecture Notes in Computer Science, vol 14447. Springer, Singapore. https://doi.org/10.1007/978-981-99-8079-6_14