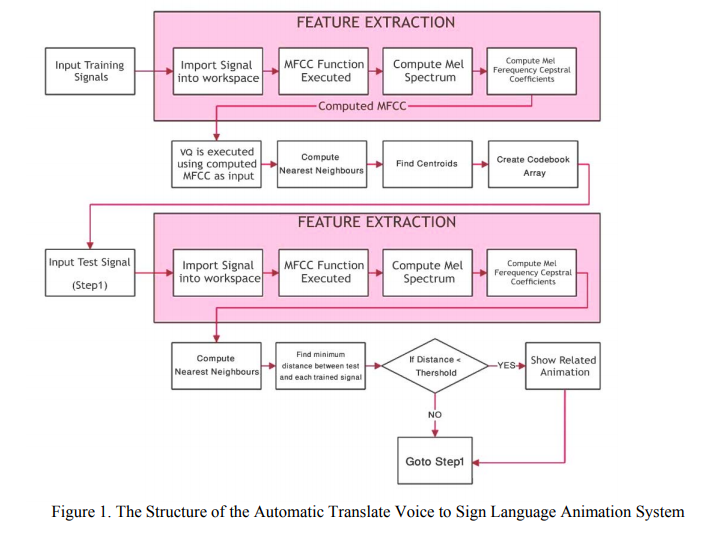
Figure 1. The Structure of the Automatic Translate Voice to Sign Language Animation System-Development an Automatic Speech to Facial Animation Conversion for Improve Deaf Lives
- 1. Young Researchers Club, Isfahan Branch (Khurasgan), Islamic Azad University,Isfahan, Iran
Description
All technologies of voice recognition, speaker identification and verification, each has its
own advantages and disadvantages and may requires different treatments and techniques. The
choice of which technology to use is application-specific. At the highest level, all voice recognition
systems contain two main modules: feature extraction and feature matching. Feature extraction is
the process that extracts a small amount of data from the voice signal that can later be used to
represent each word. Feature matching involves the actual procedure to identify the unknown word
by comparing extracted features from his/her voice input with the ones from a set of known words.
A wide range of possibilities exist for parametrically representing the speech signal for the
voice recognition task, such as Linear Prediction Coding (LPC), RASTA-PLP and Mel-Frequency
Cepstrum Coefficients (MFCC).
Notes
Files
Figure 1. The Structure of the Automatic Translate Voice to Sign Language Animation System.png
Files
(149.5 kB)
| Name | Size | Download all |
|---|---|---|
|
md5:9b55b07945874ff1b7f406c529ea6cef
|
149.5 kB | Preview Download |
{kind=link}