Doodleverse/Segmentation Zoo Res-UNet model for NOAA ERI/4-class segmentation of RGB 512x512 images

Description
This Residual-UNet model is trained on 1,179 pairs of human-generated segmentation labels and images from Emergency Response Imagery (ERI) collected by US National Oceanic and Atmospheric Administration (NOAA) after Hurricane Barry, Delta, Dorian, Florence, Ida, Laura, Michael, Sally, Zeta, and Tropical Storm Gordon. The dataset is available here: https://doi.org/10.5281/zenodo.7268082
Models have been created using Segmentation Gym:
Code - https://github.com/Doodleverse/segmentation_gym
Paper - https://doi.org/10.1029/2022EA002332
The model takes input images that are 512 x 512 x 3 pixels, and the output is 512 x 512 x 4, corresponding to 4 classes:
- water
- bare sediment
- vegetation
- development (roads, buildings, power lines, parking lots, etc.)
Included here are 6 files with the same root name:
- '.json' config file: this is the file that was used by Segmentation Gym to create the weights file. It contains instructions for how to make the model and the data it used, as well as instructions for how to use the model for prediction.
- '.h5' weights file: this is the file that was created by the Segmentation Gym function `train_model.py`. It contains the trained model's parameter weights. It can called by the Segmentation Gym function `seg_images_in_folder.py`.
- '_model_history.npz' model training history file: this numpy archive file contains numpy arrays describing the training and validation losses and metrics. It is created by the Segmentation Gym function `train_model.py`
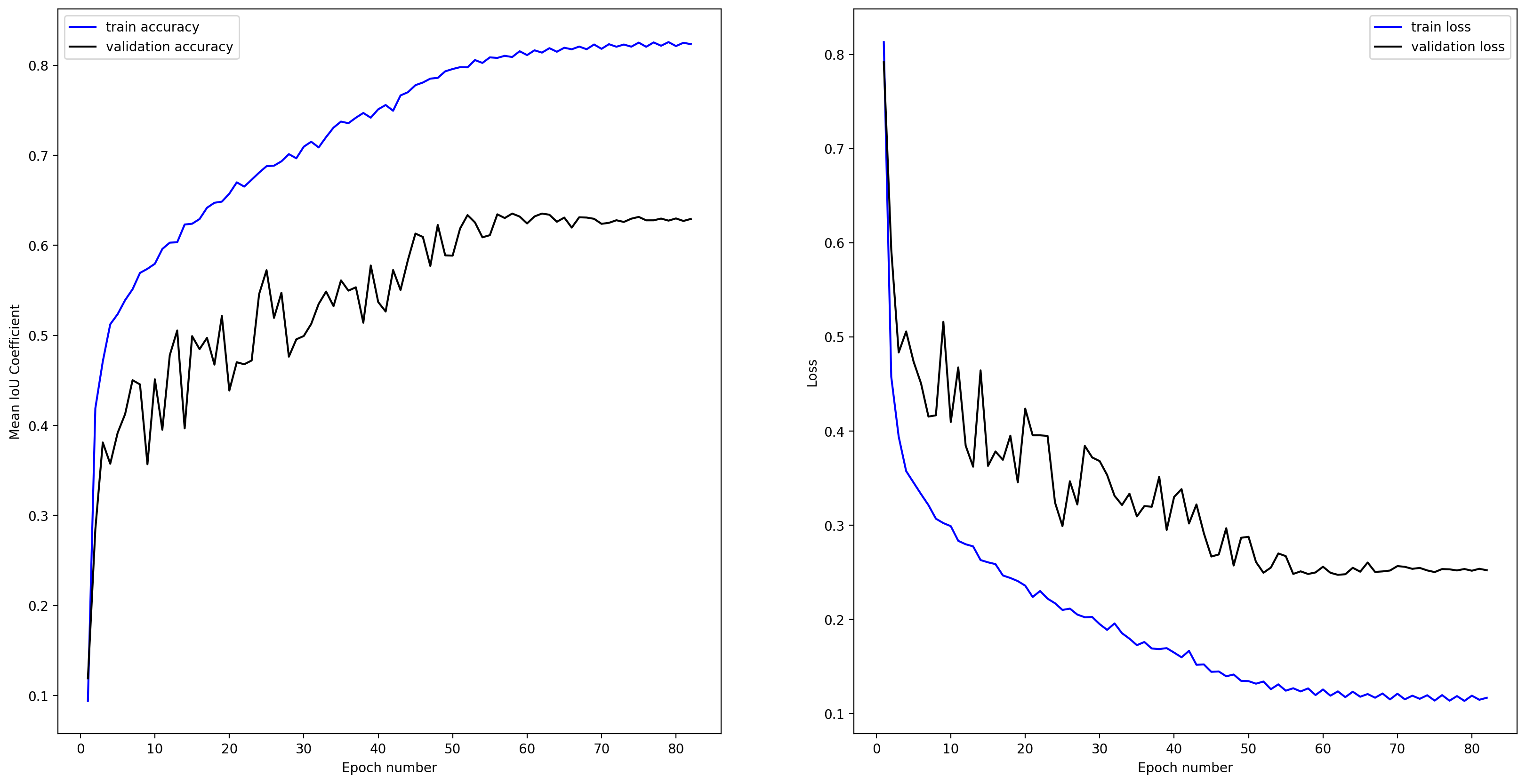
- '.png' model training loss and mean IoU plot: this png file contains plots of training and validation losses and mean IoU scores during model training. A subset of data inside the .npz file. It is created by the Segmentation Gym function `train_model.py`
- '.zip' of the model in the Tensorflow ‘saved model’ format. It is created by the Segmentation Gym function `utils/gen_saved_model.py`
- '_modelcard.json' model card file: this is a json file containing fields that collectively describe the model origins, training choices, and dataset that the model is based upon. There is some redundancy between this file and the `config` file (described above) that contains the instructions for the model training and implementation. The model card file is not used by the program but is important metadata so it is important to keep with the other files that collectively make the model and is such is considered part of the model
Additionally, BEST_MODEL.txt contains the name of the model with the best validation loss and mean IoU
Files
BEST_MODEL.txt
Files
(91.2 MB)
| Name | Size | Download all |
|---|---|---|
|
md5:47e517c746f8beebd3a6c1bff79a8f51
|
32 Bytes | Preview Download |
|
md5:50b9f2bdcbd2751bebe8a3eb7f4e7962
|
851 Bytes | Preview Download |
|
md5:a83c52df76813c0aa80e930f0ffc8da2
|
69.4 MB | Download |
|
md5:c94e12a1fc5cbebfdb6e4c32b6c450a7
|
21.5 MB | Preview Download |
|
md5:3c41fc0eddc3c8e876863605c404d3a2
|
3.9 kB | Download |
|
md5:86cccc6d8942f2f7c5abe0ebacf40f14
|
2.3 kB | Preview Download |
|
md5:037acb110fcea924be73341da795961a
|
230.1 kB | Preview Download |
{kind=link}
Additional details
Related works
- Cites
- Dataset: 10.5281/zenodo.7268083 (DOI)
- Journal article: 10.1029/2022EA002332 (DOI)